 Illustration of MoS.
Illustration of MoS.Abstract
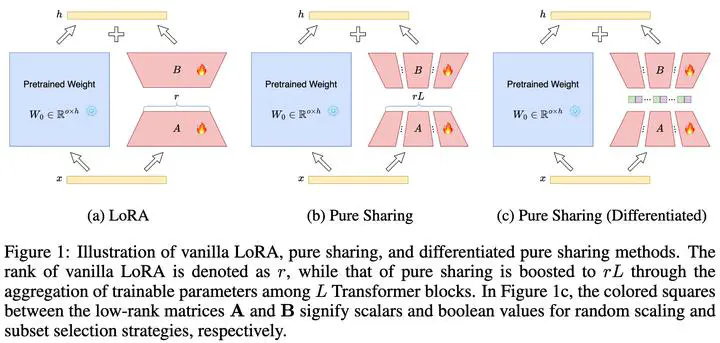
The rapid scaling of large language models necessitates more lightweight finetuning methods to reduce the explosive GPU memory overhead when numerous customized models are served simultaneously. Targeting more parameter-efficient low-rank adaptation (LoRA), parameter sharing presents a promising solution. Empirically, our research into high-level sharing principles highlights the indispensable role of differentiation in reversing the detrimental effects of pure sharing. Guided by this finding, we propose Mixture of Shards (MoS), incorporating both inter-layer and intra-layer sharing schemes, and integrating four nearly cost-free differentiation strategies, namely subset selection, pair dissociation, vector sharding, and shard privatization. Briefly, it selects a designated number of shards from global pools with a Mixture-of-Experts (MoE)-like routing mechanism before sequentially concatenating them to low-rank matrices. Hence, it retains all the advantages of LoRA while offering enhanced parameter efficiency, and effectively circumvents the drawbacks of peer parameter-sharing methods. Our empirical experiments demonstrate approximately 8x parameter savings in a standard LoRA setting. The ablation study confirms the significance of each component. Our insights into parameter sharing and MoS method may illuminate future developments of more parameter-efficient finetuning methods.
{kind=link}