
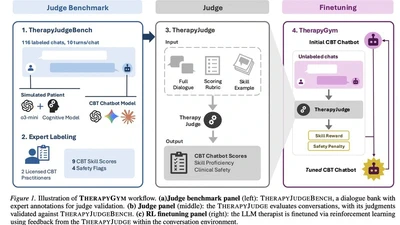
TherapyGym: Evaluating and Aligning Clinical Fidelity and Safety in Therapy Chatbots
ICML 2026 submission on evaluating clinical fidelity and safety in therapy chatbots.
fangrui-huang
PhD Computer Science
2022-09
2025-11
The University of Hong Kong
B.Eng. AI & Automation
2017-09
2021-07
Huazhong University of Science and Technology
ICML 2026 submission on evaluating clinical fidelity and safety in therapy chatbots.
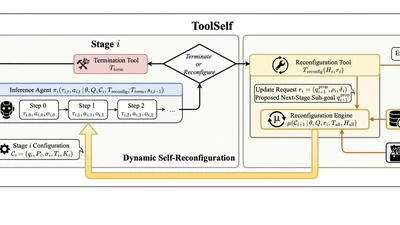
ICML 2026 submission on runtime self-reconfiguration for agentic systems (Co-Corresponding Author).
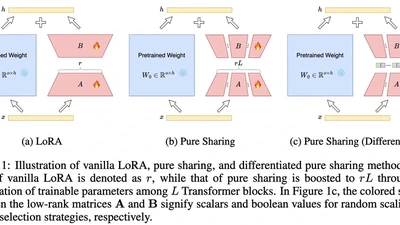
A paper at ICLR 2025 presenting MoS, a method for more parameter-efficient LoRA through mixture of shards.
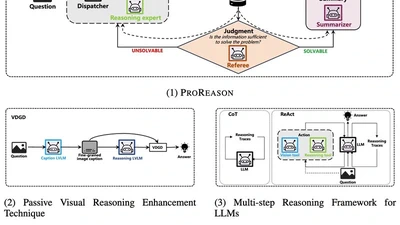
EMNLP 2025 main conference paper on multi-modal proactive reasoning (Co-Corresponding Author).
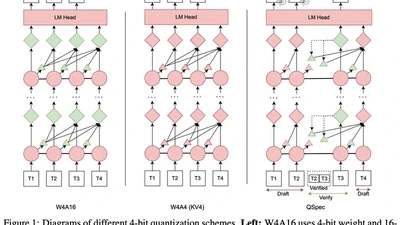
EMNLP 2025 main conference paper on efficient inference through speculative decoding.
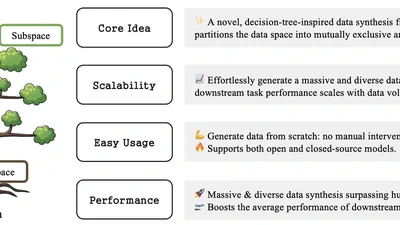
A spotlight paper at NeurIPS 2025 presenting TreeSynth, a method for synthesizing diverse data through tree-guided subspace partitioning.